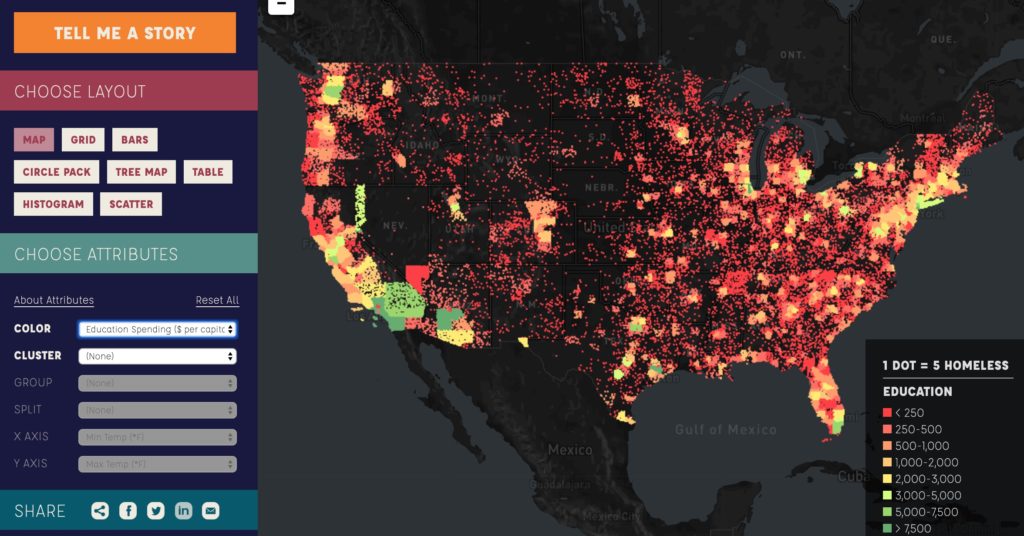
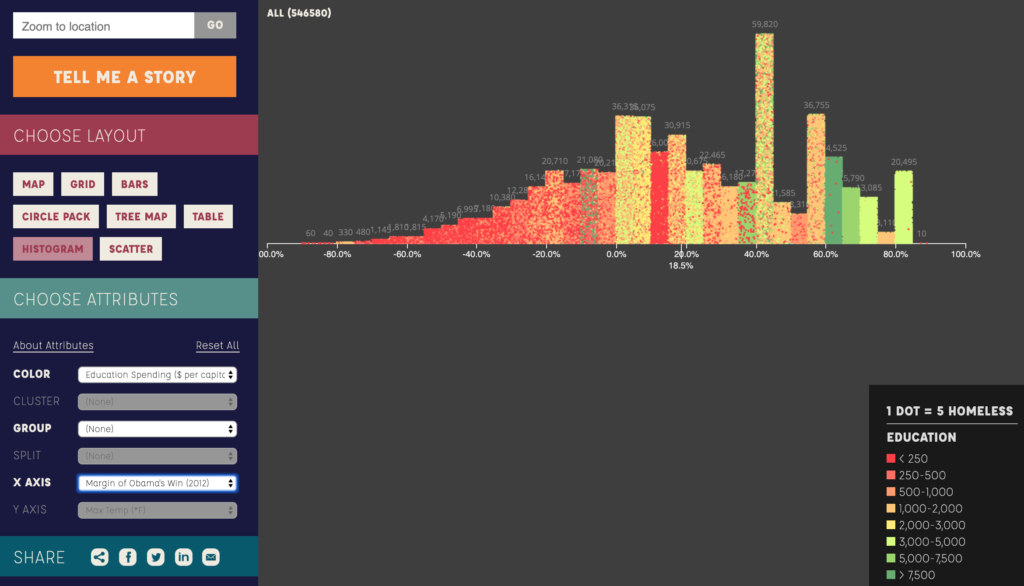
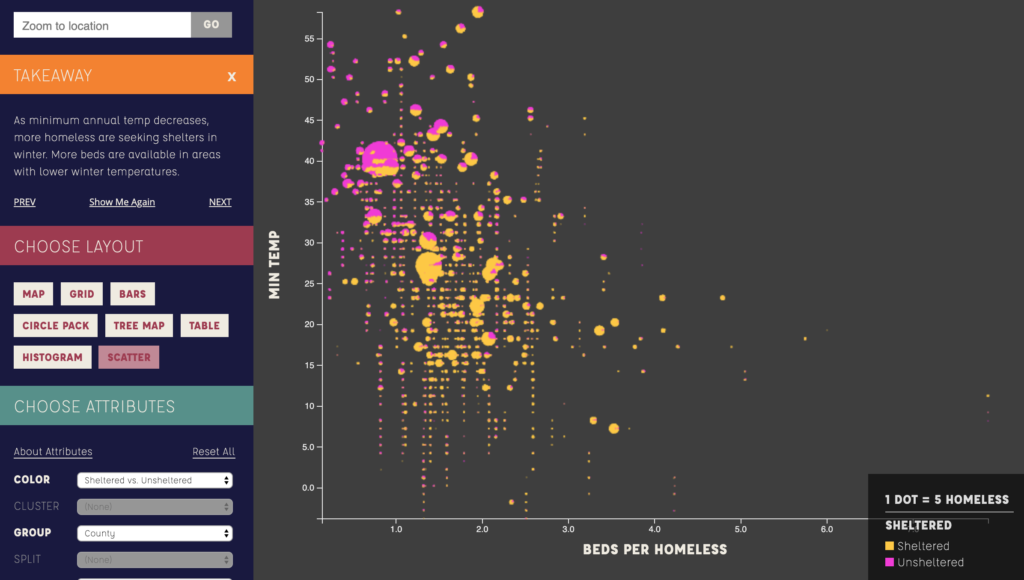
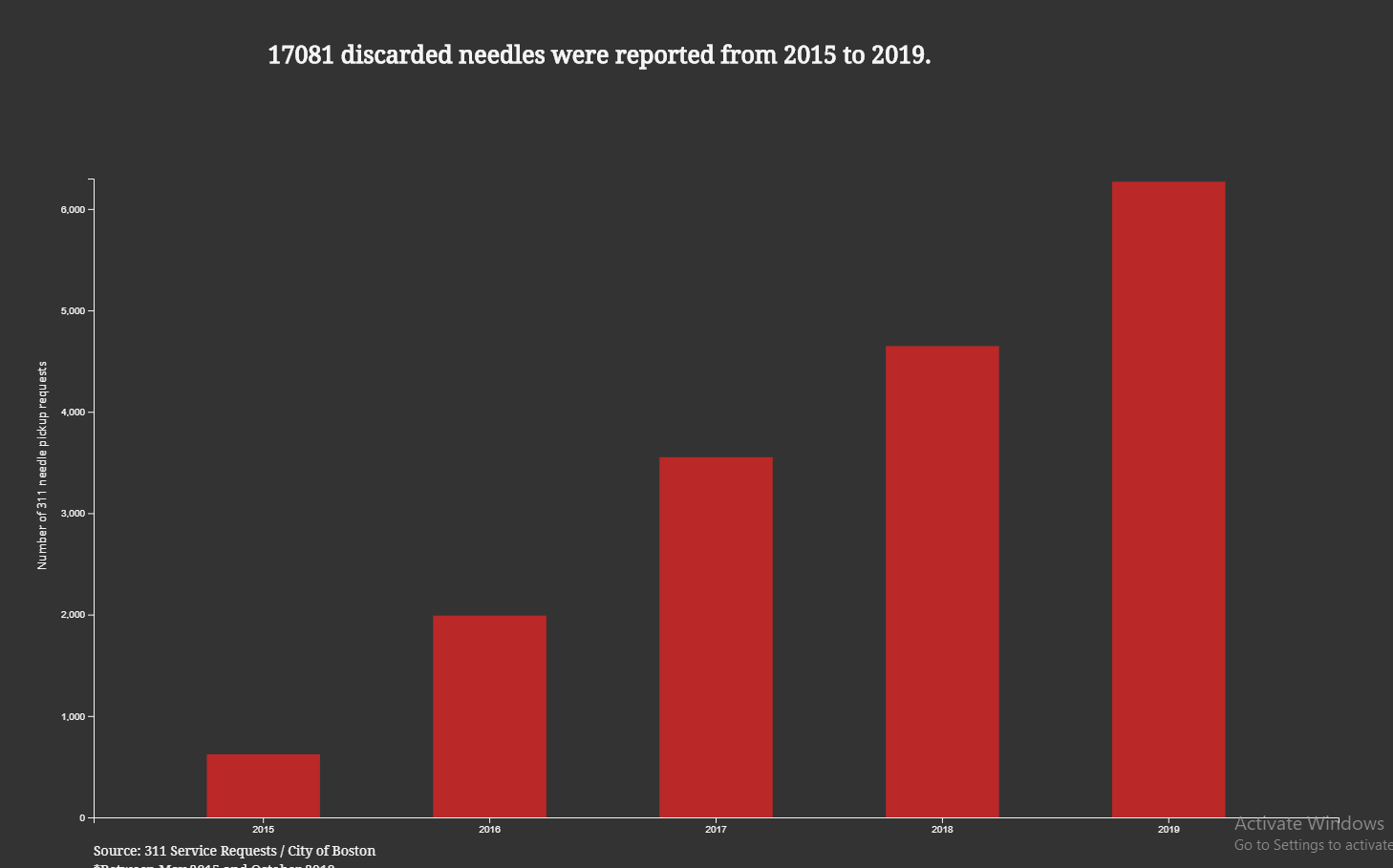
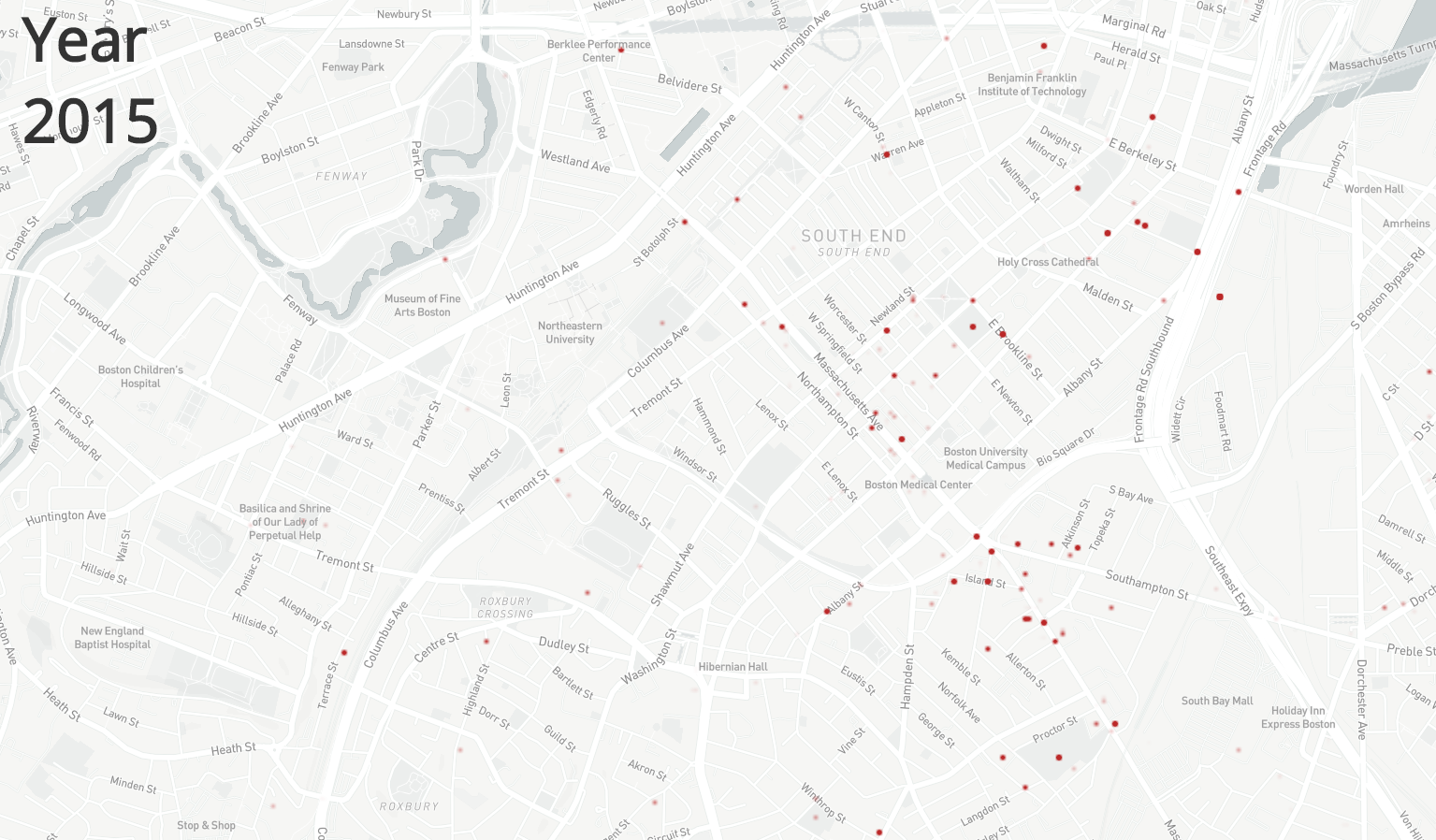
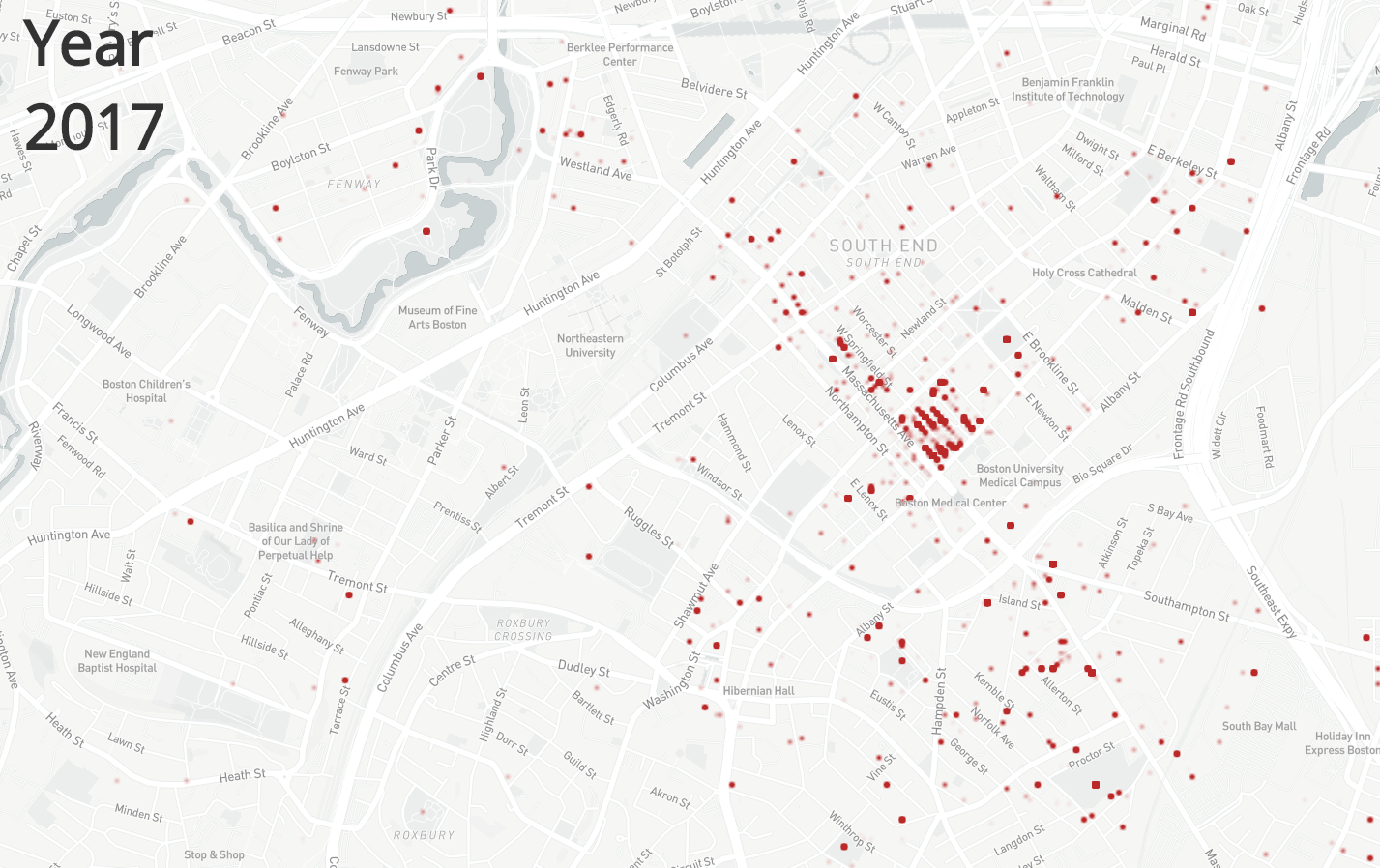
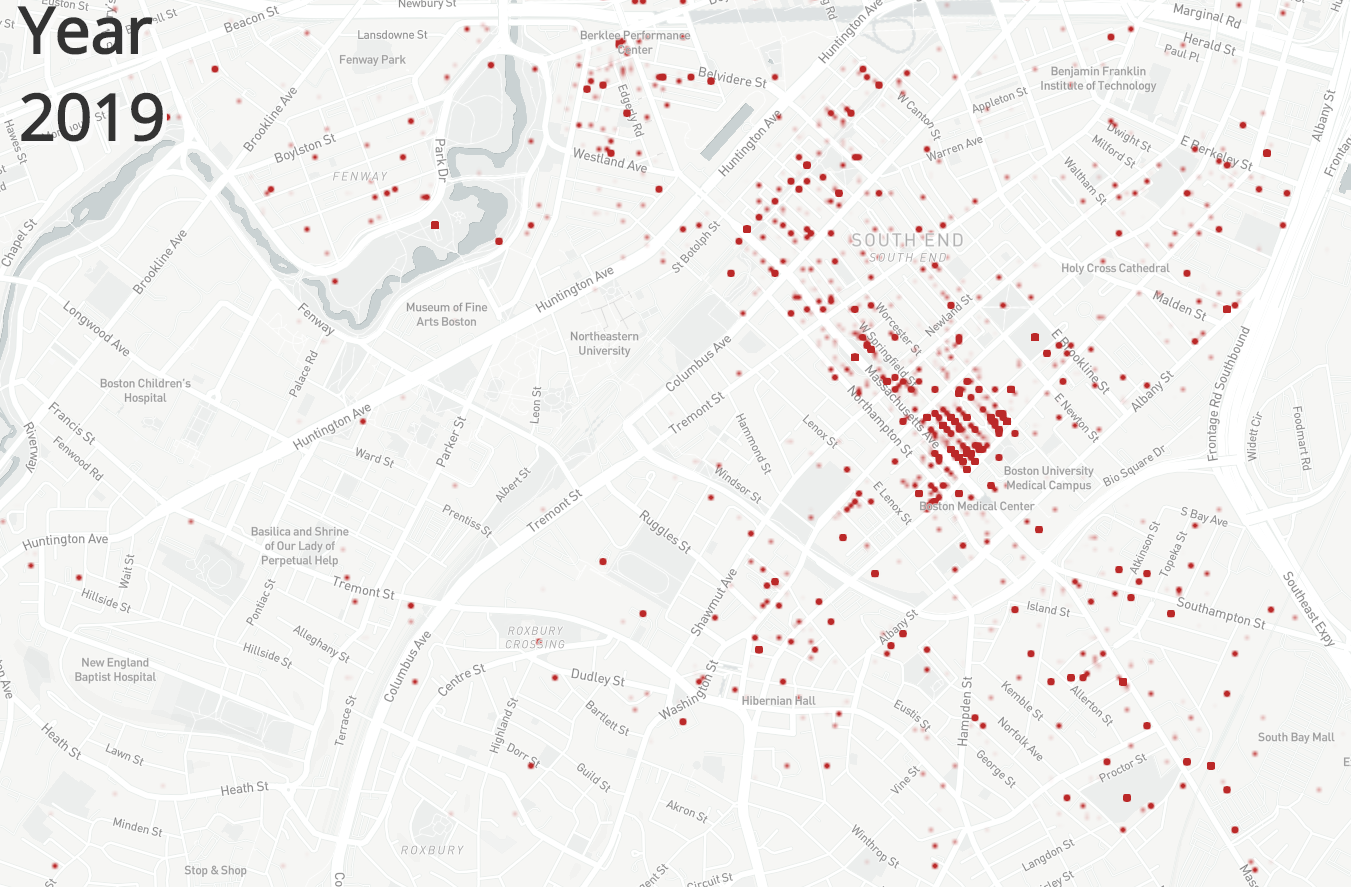
Maria Popova has always been one of my favorite writers and I found this graphic on her blog brainpickings.com. The graphic shows sleep habits and literary output for various famous writers, ordered starting with Honore de Balzac who woke up at 1am and ending with Charles Bukowski who would get up at 12pm. It packs a good amount of information into a small icon for each writer – name, lifespan, wake-up time, number of books or collections published separate by category, and awards won. A lot of the information is encoded by colors, mini bar charts and symbols that are unlabeled, which saves space but does require the reader to look at and understand the key provided. All the information included in the chart seems to have been deliberate and relevant to the question for example, writer lifespan was included for context since “length of a writing career influences the volume of literary output” as explained at the top of the chart. The chart leads the eye very clearly, with a line going through the authors presented and a meaningful ordering. The illustrations of the authors make the chart more engaging and remind the reader that there are individual humans behind the data. There’s also visual reinforcement of one of the major datasets – wake-up time – since different times appear at different points around the circle enclosing each writer’s portrait. This does mean there is a good amount of blank space in the figure since each writer’s information is centered for consistency but there needs to be a wide spacing to handle the bar charts of productivity pointing in different directions. I do think this chart is not as effective seen on a large scale – it is meant to be viewed as a poster, but it’s hard to see anything viewing the entire chart in a browser window for example. It’s harder to see overall trends since the individual information is too small when the chart is viewed as a whole. It’s only when you zoom in on a specific writer that the data starts to come into focus. This chart seems to be aimed at people who are interested in literature and potentially those who are interested in optimizing their daily routines for productivity. For people who are willing to spend some time and zoom in on the writers – or maybe just look at their favorite writers – this chart is a fun look into how famous writers lived their lives and a chance to consider how much wake-up time could affect literary productivity.