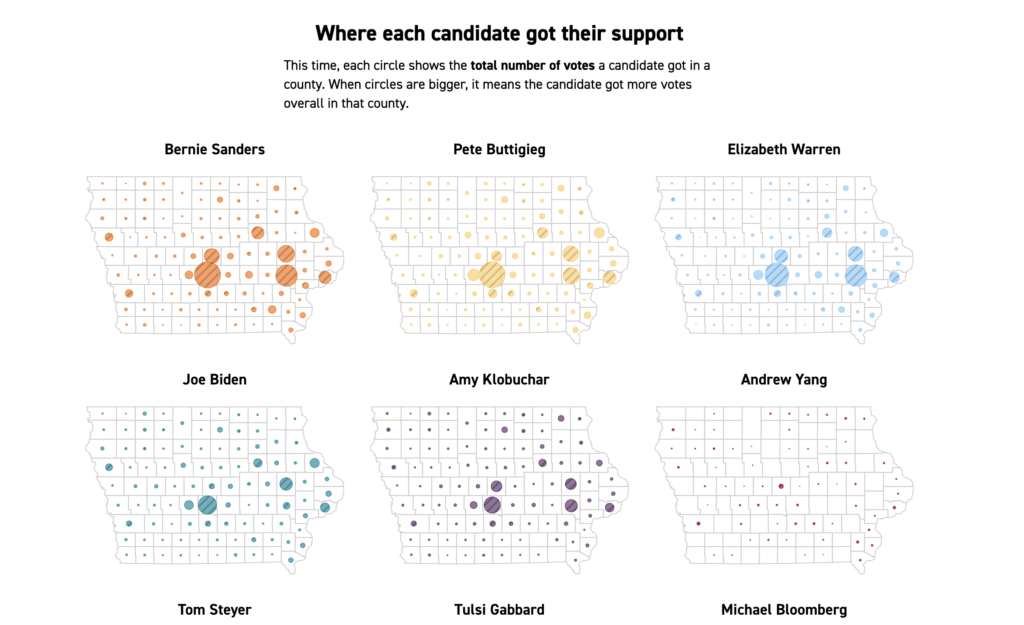
Data presentation blog post by Eugenio Zuccarelli

In a world filled with buzzwords ranging from Internet of Things to AI and Edge Computing, navigating the innovation space can be quite tricky.
One aspect shared by mostly all the innovative technologies though, is the general trend they follow, starting from low key discoveries, until reaching maturity and widespread use.
Gartner, a global research and advisory firm, developed a general framework that captures all innovative technologies and maps them into a specific framework.
This framework, called Hype Cycle for Emerging Technologies, shows the general trend followed by technologies over time, mapping society’s expectations towards each innovation.
In particular, the chart lists all current technologies on x-y axes, where the position determines the general expectation over time. The innovations start from an “Innovation Trigger”, propelling them to peak hype, then to a minimum point for then coming back again at a more moderate pace, reaching stable progress.
By showing such information in a conceptual form, rather than being data-heavy, the Hype Cycle can be used to reach any audience. Indeed, the simple and relatable concepts expressed by the chart can be understood by any person with knowledge of the “common buzzwords”.
However, the chart can be even more useful for technical people, with a strong understanding of the technology environment that can benefit from using or investing in the technology.
Overall, the Hype Cycle aims at giving context to emotionally-inflated concepts such as AI, IoT and Cloud Computing. These concepts are usually able to capture the interest of the masses, but then showing similar patterns of disillusionment. Here, Gartner’s cycle successfully clarifies that some technologies are still in the early stages and overinflated, while other technologies have almost reached maturity, and are ready to become part of our daily lives.