Team: Josh Feldman, Samra Lakew, Neil Pendse
Initial Iteration: https://datastudio2020.datatherapy.org/2020/04/22/data-story-telling-studio-sketch-3-air-filters/
Changes in this iteration:
Based off the feedback we received from the class in our initial iteration, we changed the following in our data story:
- We removed references to changes in air pollution caused by the coronavirus in order to simplify the design
- We heard that the scrolling to see different time periods was confusing, so we removed that feature.
- We made the data story more interactive by only showing the clean air filter once the user signed up for the campaign
- We added Greenpeace branding
- We only map the air quality index to color and not to the width of the bar, since we heard that it wasn’t clear that the bar changed based on your location.
Audience:
Our audience remained the same. Our intended target audience is under 40 because they will have to live with the effects of poor air quality. If Greenpeace gains their ongoing support, it will ensure the continuity of our organization and movement. There is no specific region we are targeting with this campaign.
Goals
Our goals were to:
- Increase signatures for this Greenpeace campaign on clean air
- Engage our audience in the fight for clean air
- Increase support for Greenpeace
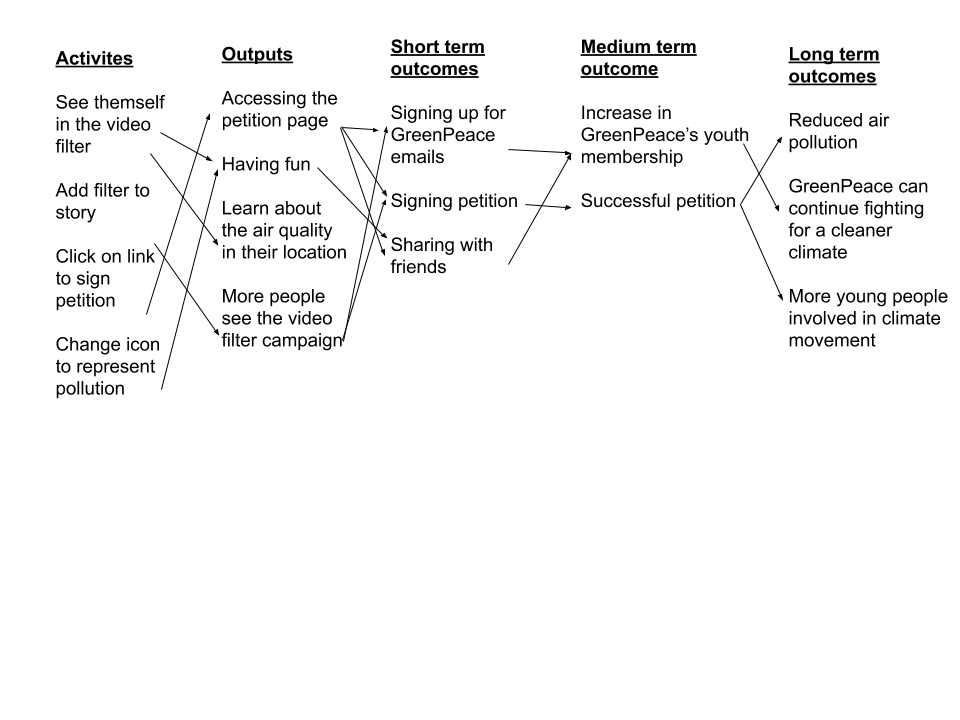
We based these goals off of our logic modelling exercise.
Test Plan
To evaluate our campaign, we made an online form where users would complete a pre-survey, try a static version of our data story, and complete a post survey.
Results
We received 20 responses to our survey. 95% of our respondents were between 20 and 30 years old, which is within our target audience. While we can make some tentative conclusions about how users in this age range respond to the data story, it is unclear how those under 20 or in their thirties will react to the campaign. While limited with respect to age, our sample covered a few different types of locations including Beijing, Singapore, New York, Los Angeles, New Delhi, and Cambridge (MA).
Positive feedback:
- 100% of respondents understood that it was a Greenpeace’s project
- Positive impressions of Greenpeace grew from 17.6% to 70.6%
- 94.1% of people said they had fun with the filter!
- The proportion of people saying they were not likely to take action to improve air quality in their location dropped from 40% to 20% (though all of these people changed to the “somewhat likely” category)
These results suggest that our current iteration of the data story is improving millenial’s perception of Greenpeace and that they had fun with the filter. There was also some evidence that the data story made it more likely that our users will take action to reduce air pollution, but very few respondents were confident that they would do so. Ideally we would follow up with our users to see if their behaviour changed.
Negative feedback:
- 58.8% of people were “somewhat likely” to share the filter
- Users did not change their opinion on the quality of air in their location
- 64.7% said they would sign up for the newsletter.
The negative feedback we observed in the surveys suggests that we need to learn more about why users don’t want to share the filter. It is also interesting that many users said they had fun with the filter and felt like the air quality in their area was poor, but didn’t sign up for the campaign. We need to learn more about the barriers preventing users from signing up for the campaign.
In the free text sections of the survey, we got the feedback that we should change some stylistic aspects of the filter:
- “Simpler explanation for laymen”
- “poop emojis in the filter were a bit excessive tbh”
- “the filter should be more appalling”
This suggests that the playful tone we took might not be most effective for this subject. We should experiment with how users respond to a serious/appalling story in a medium that is typically light hearted.
Conclusions
- Our current iteration of the data story is improving millenial’s perception of Greenpeace
- Our audience is having fun with the video filters
- There is some suggestive evidence that our audience is being motivated to take action to fight air pollution – we should follow up on this.
- We need to learn more about why users don’t want to share the filter.
- We need to learn more about the barriers preventing users from signing up for the campaign.
- We should experiment with how users respond to a serious/appalling story in a medium that is typically light hearted.